
Imagine a world where a computer can glance at a photograph and tell you if there’s a cat hiding in the frame, or even spot the faintest sign of cancer in a medical scan—sometimes faster and more accurately than a human. That world is not just the stuff of science fiction, but our present reality. The journey to make machines “see” and “understand” things the way we do is filled with both wonder and challenge. Teaching an algorithm to recognize something as familiar as a cat, or as critically important as cancer, is both an art and a science—a process that pulls back the curtain on the marvels and mysteries of artificial intelligence. What does it really take to make a machine see the world through our eyes?
From Pixels to Perception: The First Steps in Machine Learning

The process starts with something surprisingly humble: raw data. For an algorithm to learn what a cat looks like, it needs thousands, sometimes millions, of images. These images are nothing more than grids of colored dots, or pixels, to a machine. While humans can instantly spot a whisker or a tail, computers need guidance to make sense of these patterns. The first step is to feed the algorithm a massive amount of visual data, each image carefully labeled as “cat” or “not cat.” This labeled data becomes the foundation for learning. Without it, the algorithm is as lost as a tourist without a map in a foreign city.
Teaching by Example: The Role of Labeled Data

Labeled data is like the alphabet for algorithms. Every image tagged with “cat” or “cancer” acts as a teaching moment. Imagine showing a child hundreds of photos and saying, “This is a cat, that is not.” Over time, the child starts to pick up on subtle clues—the pointy ears, the curious eyes, the arch of a back. In machine learning, this process is called supervised learning. The more examples the algorithm sees, the better it gets at distinguishing patterns that separate cats from dogs, or healthy cells from cancerous ones. This step requires painstaking work by humans, who must manually tag vast datasets before the computer can even begin to learn.
Algorithm Architecture: Building the Brain

Once the data is ready, it’s time to construct the machine’s “brain.” This brain, known as a neural network, is inspired by the human brain’s structure, with layers of interconnected “neurons” that process information. Each layer of the network learns to detect more complex features—edges, shapes, and eventually, entire objects. Designing these architectures is as much about creativity as it is about science. Researchers experiment with different shapes and sizes of networks, much like architects design buildings for specific purposes. The right architecture can mean the difference between a system that spots every cat or one that misses the obvious.
The Magic of Training: Adjusting Weights and Biases

Training a neural network is where the magic—and the math—happens. The algorithm makes guesses about each image’s content, and when it’s wrong, it adjusts its internal settings, called weights and biases. This adjustment is like a teacher correcting a student’s homework, again and again, until the student gets it right. This feedback loop is powered by a process called backpropagation. Over thousands of cycles, the network fine-tunes itself, gradually getting better at recognizing cats or cancer cells. The more feedback it receives, the sharper its “eyes” become.
Validation and Testing: Proving the Machine’s Skills

But how do we know if the machine has truly learned? That’s where validation and testing come in. After training, the algorithm is tested on new images it has never seen before. This is like quizzing a student with questions from outside the textbook. If the algorithm performs well on this unseen data, we know it has learned real-world patterns, not just memorized answers. This step is crucial, especially in healthcare, where a false negative could be catastrophic.
Dealing with Errors: When Machines Get It Wrong

Even the smartest machines make mistakes. Recognizing a fluffy pillow as a cat or missing a subtle tumor in a scan are more than just technical errors—they can have serious consequences. Scientists spend countless hours analyzing these mistakes, tweaking the algorithm, and adding more examples to help the machine learn from its errors. This process of trial and error is ongoing. It’s a reminder that perfection is elusive, but with every mistake, the machine gets a little bit smarter.
The Challenge of Bias: Fairness in Machine Learning

Machines can only learn from the data they are given. If the dataset mostly contains pictures of tabby cats, the algorithm might struggle with Siamese cats or black cats. In medicine, if the algorithm is trained mostly on scans from one population, it may not work as well for others. This problem, known as bias, is a serious challenge. Researchers must carefully select diverse and representative data to ensure fairness and accuracy. Otherwise, the algorithm might make decisions that are unfair or even dangerous.
Transfer Learning: Teaching Old Dogs New Tricks
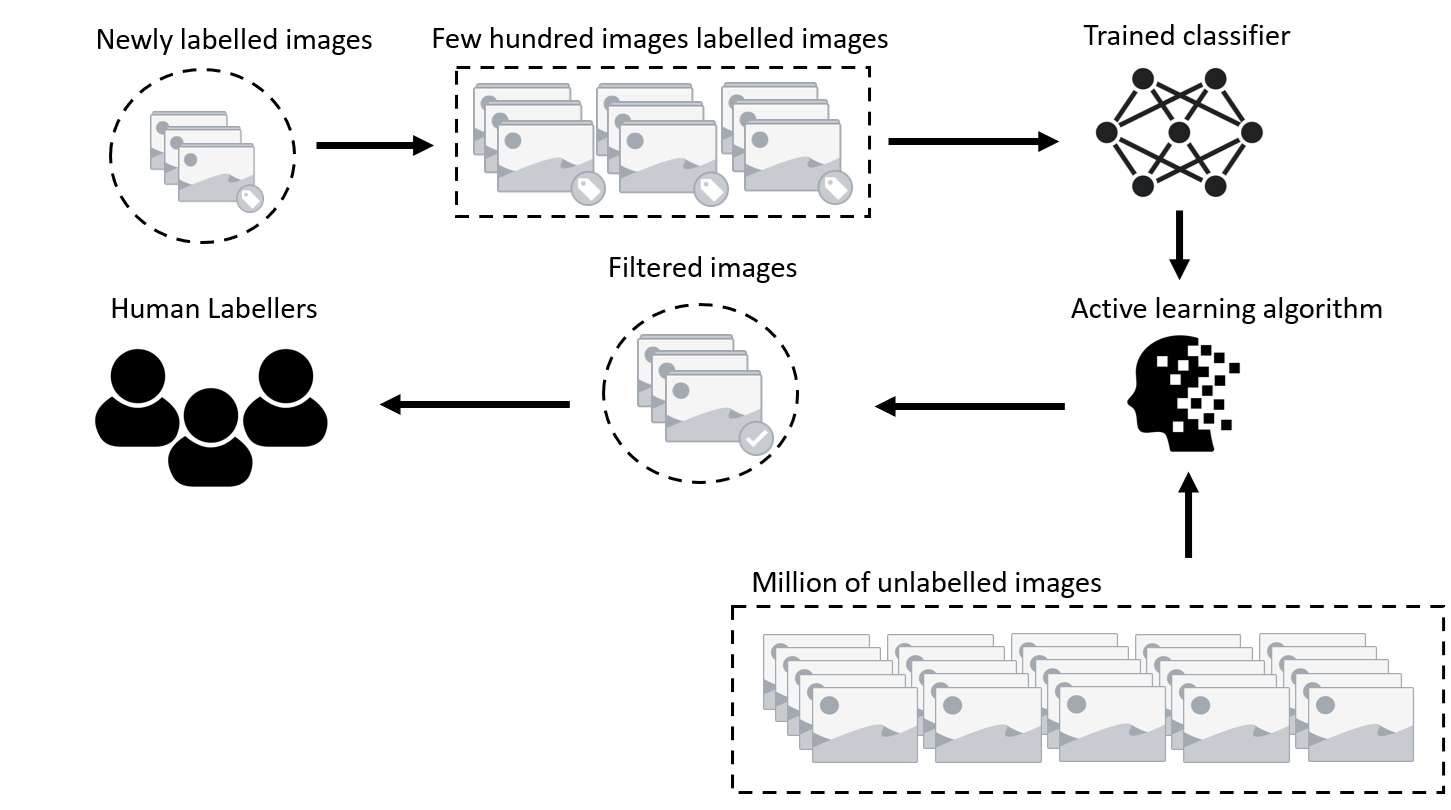
Sometimes, researchers speed up the process by using “transfer learning.” Instead of starting from scratch, they take an algorithm already trained to recognize general objects and fine-tune it to spot something specific, like a rare breed of cat or a certain type of cancer. This approach saves time and resources, making it possible to tackle problems with limited data. It’s like teaching a musician who knows the piano to play the organ—the basics are there; they just need to learn the differences.
Human and Machine: Working Together

Despite their power, machines are not replacing humans—they are becoming our partners. In hospitals, algorithms help doctors spot early signs of disease, acting as a second pair of eyes. In everyday life, they help us organize photos or filter spam emails. The key is collaboration: humans provide context, judgment, and empathy, while machines offer speed, consistency, and the ability to process vast amounts of data. Together, they can achieve more than either could alone.
The Future of Recognition: Beyond Cats and Cancer

The boundaries of what machines can recognize are expanding every day. From identifying endangered species in the wild to spotting fake news online, the possibilities are breathtaking. As technology advances, algorithms will become even better at seeing the world as we do—maybe even better. The journey is far from over, and the next breakthrough could be just around the corner.
Why It Matters: The Heart of Machine Learning

At its core, teaching a machine to recognize a cat or cancer is about more than technology. It’s about giving computers the tools to help us understand and care for our world, whether that means finding a lost pet or saving a life. The process is complex, demanding patience, creativity, and an unwavering commitment to fairness. As we continue to teach our machines, we’re also learning about ourselves—our strengths, our blind spots, and our endless curiosity. What would you want a machine to recognize next?


